CSV files
Naming of files
A naming strategy provides a mapping between model classes and the human readable names of those entities to be used within e.g. the data sinks, in which the serialized representation of several objects of this class can be found. Currently we offer two different, pre-defined naming strategies, which you might extend to fit your needs:
EntityPersistenceNamingStrategy: A basic naming strategy that is able to add prefix and suffix to the names of the entities. A flat folder structure is considered. For more details see Default naming strategy.
HierarchicFileNamingStrategy: An extended version of the EntityPersistenceNamingStrategy. Additionally, the Default directory hierarchy is taken into account. Please note, that this directory hierarchy is only meant to be used in conjunction with input models.
However, you can control the behaviour of serialization and de-serialization of models by injecting the desired naming
strategy you like into CsvDataSource and CsvFileSink.
Default naming strategy
There is a default mapping from model class to naming of entities in the case you would like to use csv files for
(de-)serialization of models.
You may extend / alter the naming with pre- or suffix by calling new EntityPersistenceNamingStrategy("prefix","suffix").
Inputs
Model |
File Name |
|---|---|
operator |
prefix_ operator_input _suffix |
node |
prefix_ node_input _suffix |
line |
prefix_ line_input _suffix |
switch |
prefix_ switch_input _suffix |
two winding transformer |
prefix_ transformer2w_input _suffix |
three winding transformer |
prefix_ transformer3w_input _suffix |
measurement unit |
prefix_ measurement_unit_input _suffix |
biomass plant |
prefix_ bm_input _suffix |
combined heat and power plant |
prefix_ chp_input _suffix |
electric vehicle |
prefix_ ev_input _suffix |
electric vehicle charging station |
prefix_ evcs_input _suffix |
fixed feed in facility |
prefix_ fixed_feed_in_input _suffix |
heat pump |
prefix_ hp_input _suffix |
load |
prefix_ load_input _suffix |
photovoltaic power plant |
prefix_ pv_input _suffix |
electrical energy storage |
prefix_ storage_input _suffix |
wind energy converter |
prefix_ wec_input _suffix |
Time Series
Model |
File Name |
|---|---|
individual time series |
prefix_ its _columnScheme_UUID _suffix |
load profile input |
prefix_ lpts _profileKey _suffix |
Results
Model |
File Name |
|---|---|
node |
prefix_ node_res _suffix |
line |
prefix_ line_res _suffix |
switch |
prefix_ switch_res _suffix |
two winding transformer |
prefix_ transformer2w_res _suffix |
three winding transformer |
prefix_ transformer3w_res _suffix |
biomass plant |
prefix_ bm_res _suffix |
combined heat and power plant |
prefix_ chp_res _suffix |
electric vehicle |
prefix_ ev_res _suffix |
electric vehicle charging station |
prefix_ evcs_res*_suffix* |
fixed feed in |
prefix_ fixed_feed_in_res _suffix |
heat pump |
prefix_ hp_res _suffix |
load |
prefix_ load_res _suffix |
photovoltaic power plant |
prefix_ pv_res _suffix |
storage |
prefix_ storage_res _suffix |
wind energy converter |
prefix_ wec_res _suffix |
thermal house model |
prefix_ thermal_house_res _suffix |
cylindrical thermal storage |
prefix_ cylindrical_storage_res _suffix |
Default directory hierarchy
Although there is no fixed structure of files mandatory, there is something, we consider to be a good idea of structuring things. You may either ship your csv files directly in this structure or compress everything in a .tar.gz file. However, following this form, we are able to provide you some helpful tools in obtaining and saving your models a bit easier.
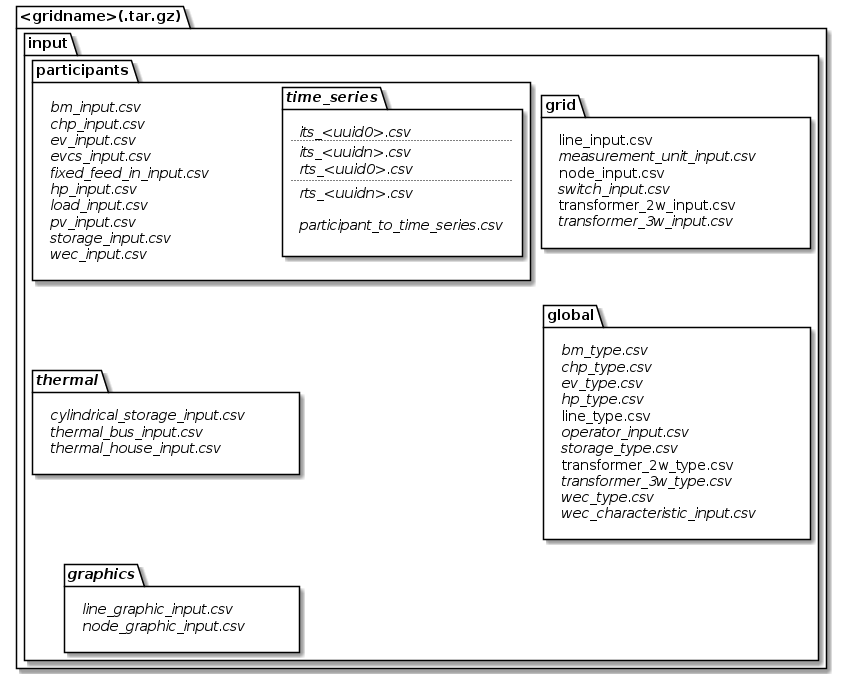 Default directory hierarchy for input classes
Default directory hierarchy for input classes
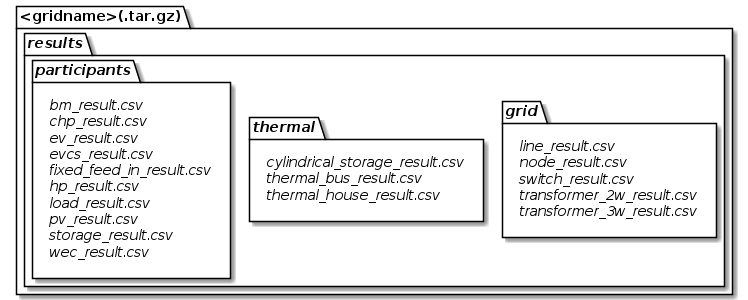 Default directory hierarchy for result classes
Default directory hierarchy for result classes
The italic parts are optional and the others are mandatory. As you see, this still is a pretty flexible approach, as you only need to provide, what you really need. However, note that this hierarchy is only meant to be used in conjunction with input models, yet.
The class DefaultInputHierarchy offers some helpful methods to validate and create a default input file
hierarchy.
De-serialization (loading models)
Having an instance of Grid Container is most of the time the target whenever you load your grid. It consists of the three main blocks:
Those blocks are also reflected in the structure of data source interface definitions. There is one source for each of the containers, respectively.
As a full data set has references among the models (e.g. a line model points to its’ nodes it connects), there is a
hierarchical structure, in which models have to be loaded.
Therefore, the different sources have also references among themselves.
An application example to load an exampleGrid from csv files located in ./exampleGrid could look like this:
/* Parameterization */
String gridName = "exampleGrid";
String csvSep = ",";
String folderPath = "./exampleGrid";
EntityPersistenceNamingStrategy namingStrategy = new EntityPersistenceNamingStrategy(); // Default naming strategy
/* Instantiating sources */
TypeSource typeSource = new CsvTypeSource(csvSep, folderPath, namingStrategy);
RawGridSource rawGridSource = new CsvRawGridSource(csvSep, folderPath, namingStrategy, typeSource);
ThermalSource thermalSource = new CsvThermalSource(csvSep, folderPath, namingStrategy, typeSource);
SystemParticipantSource systemParticipantSource = new CsvSystemParticipantSource(
csvSep,
folderPath,
namingStrategy,
typeSource,
thermalSource,
rawGridSource
);
EnergyManagementSource emSource = new EnergyManagementSource(typeSource, dataSource);
/* Loading models */
RawGridElements rawGridElements = rawGridSource.getGridData().orElseThrow(
() -> new SourceException("Error during reading of raw grid data."));
SystemParticipants systemParticipants = systemParticipantSource.getSystemParticipants().orElseThrow(
() -> new SourceException("Error during reading of system participant data."));
Try<EnergyManagementUnits, SourceException> emUnits =
Try.of(
() -> new EnergyManagementUnits(new HashSet<>(emSource.getEmUnits(operators).values())),
SourceException.class);
JointGridContainer fullGrid = new JointGridContainer(
gridName,
rawGridElements,
systemParticipants,
emUnits.getOrThrow()
);
As observable from the code, it doesn’t play a role, where the different parts come from. It is also a valid solution, to receive types from file, but participants and raw grid elements from a data base. Only prerequisite is an implementation of the different interfaces for the desired data source.
Serialization (writing models)
Serializing models is a bit easier:
/* Parameterization */
String csvSep = ",";
String folderPath = "./exampleGrid";
EntityPersistenceNamingStrategy namingStrategy = new EntityPersistenceNamingStrategy();
boolean initEmptyFiles = false;
/* Instantiating the sink */
CsvFileSink sink = new CsvFileSink(folderPath, namingStrategy, initEmptyFiles, csvSep);
sink.persistJointGridContainer(grid);
The sink takes a collection of model suitable for serialization and handles the rest (e.g. unboxing of nested models) on its own. But caveat: As the (csv) writers are implemented in a concurrent, non-blocking way, duplicates of nested models could occur.
Compression and extraction of files
We consider either regular directories or compressed tarball archives
(*.tar.gz) as source of input files.
The class TarballUtils offers some helpful functions to compress or extract input data files for easier shipping.